Coffee Codex - The flaws of the CAP Theorem
Introduction
I’m at Dote Cafe in Bellevue, WA, and today I’m learning about the CAP theorem and why it might not be correct. Last week I attended a great talk by Marc Brooker (VP/Distinguished Engineer at AWS) where he explained some information about how his team built Aurora DSQL. The talk was very interesting, but there was one part that I found very interesting and funny around 1:11:30 which is about the CAP Theorem.
Specifically Marc says something like this:
I do versions of this talk for AWS customers often and about half of the time they say, “No what you’re saying is impossible, you can’t have consistency and availability during a partition, this is not something that exists in the universe”… Fortunately it is something that exists in the universe
He’s saying that, with quorum-based replication, you can still have consistency and high availability for almost all clients, even if the strict CAP definition would rule that out.

The CAP Theorem
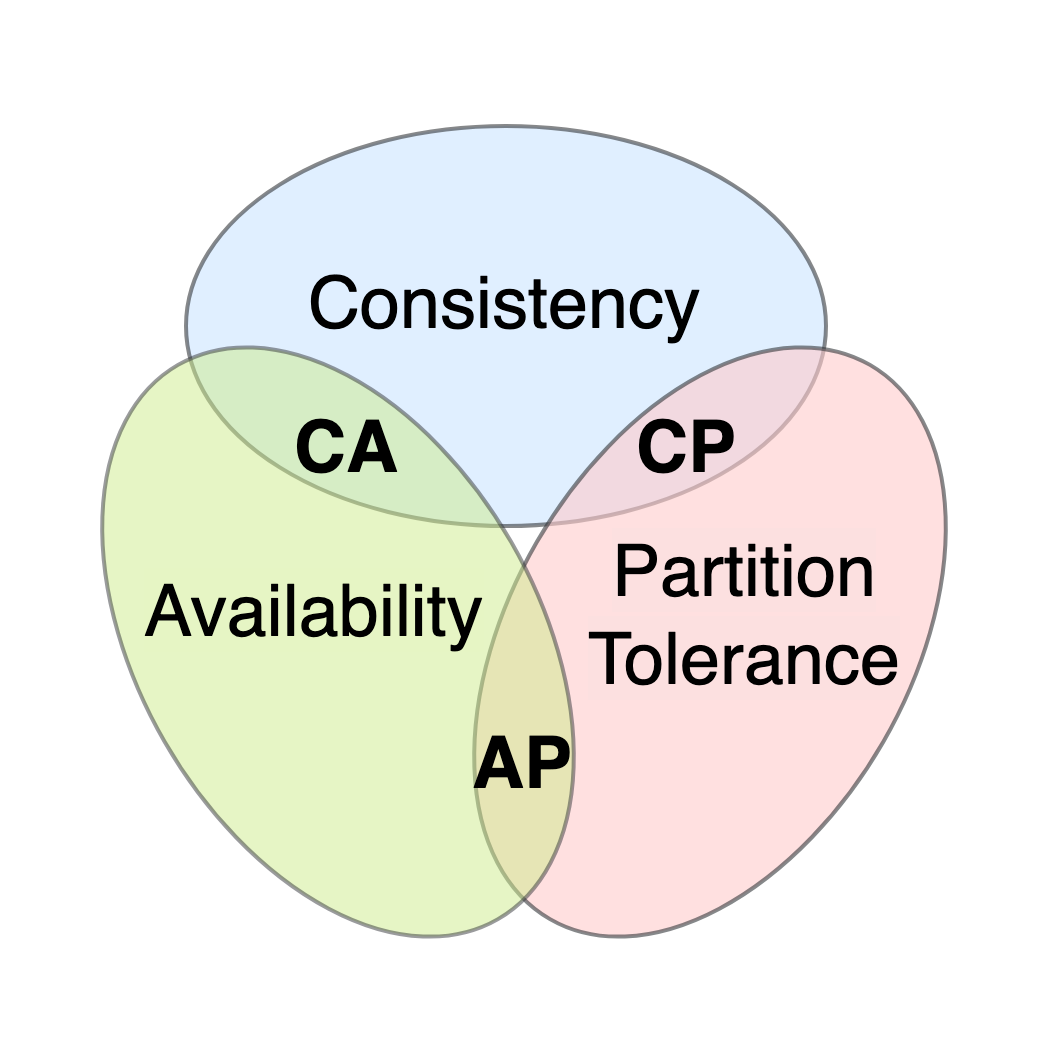
The CAP theorem is often misrepresented as saying you must “choose two out of three” from Consistency (all requests see the most up-to-date data), Availability (every request receives a response), and Partition Tolerance (the system continues to function even when the network is split). But that framing is misleading since in any real distributed system, you can’t just opt out of partition tolerance. The theorem actually shows that when a partition occurs, you must choose whether to preserve consistency or availability.
Let’s consider an example:
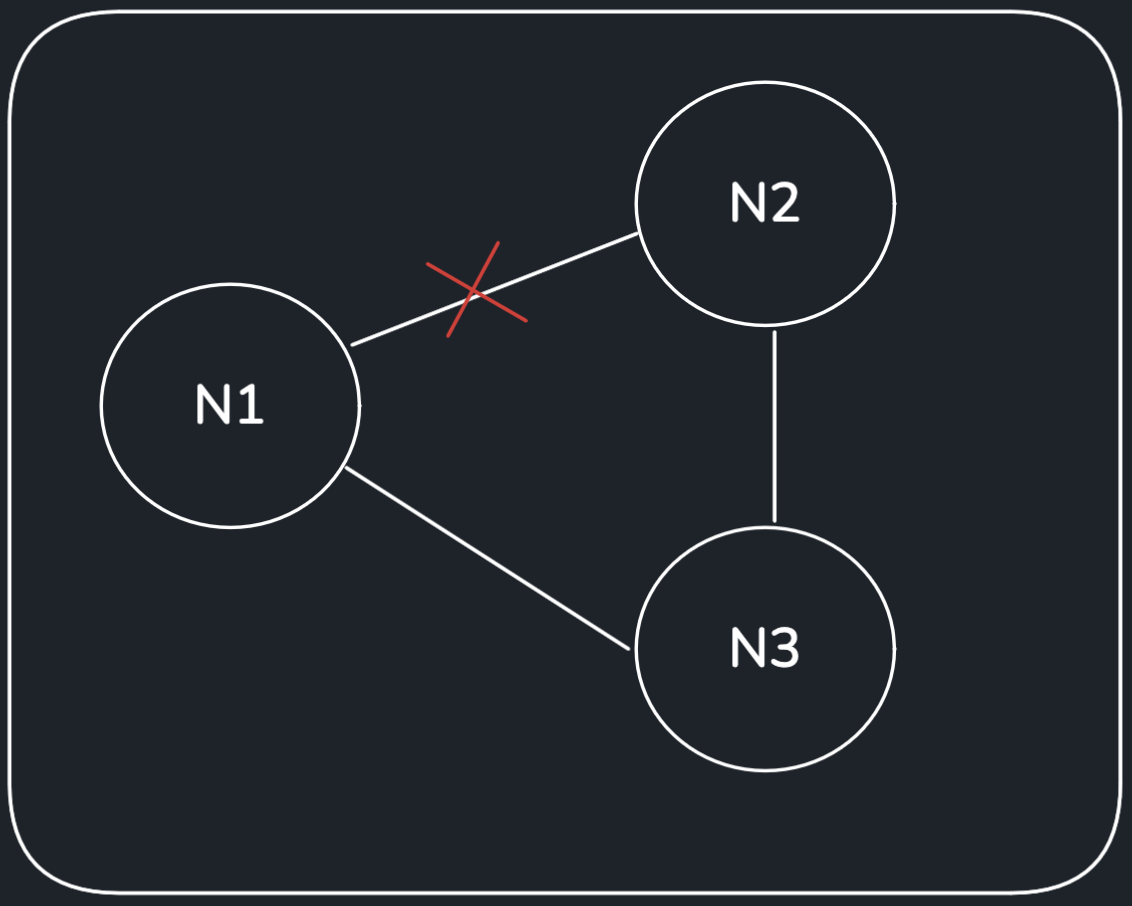
Here, if a request comes in while Node 3 can’t be reached, the system can choose to continue to allow requests (prioritizing availability) even though Node 3 might have a different view of the data, or the system can choose to fail requests (prioritizing consistency) until all nodes have the same view of the data.
Problem
The main point Marc is making is that the CAP theorem isn’t very interesting and “irrelevant for almost all engineers building cloud-style distributed systems”. The definition of availability in the formalization of the CAP theorem is “every request received by a non-failing node in the system must result in a response”.
A more complete view looks something like this from Bernstein and Das:
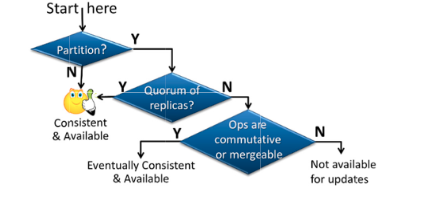
Consider this situation:
 Source: Marc’s blog
Source: Marc’s blog
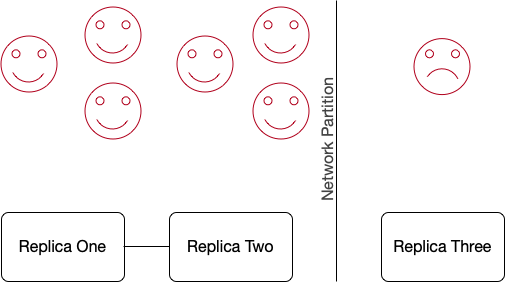
The seventh client is making a request to a replica that has experienced a network partition. Even though N - 1 clients are experiencing no trouble, the definition of availability would mean that this system would be considered unavailable.
7th client
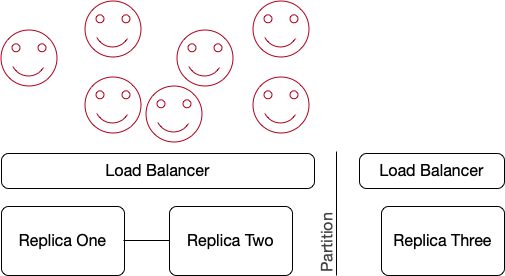
Of course we want to make the 7th client happy too, so we can achieve a quorum of the replicas. This means Replica 2 and Replica 3 continue to operate together while Replica 1 recovers. In reality, all requests are routed through a load balancer which means the seventh client’s request will be routed to one of the replicas in the quorum.
 Source: Marc’s blog
Source: Marc’s blog
When all N replicas fail, then we must accept the lack of availability because there is no other option (all nodes are down) and we have bigger problems.
When is it useful
The CAP theorem does have its uses, specifically in environments with spotty connections such as IoT or mobile. In these cases, applications can make the choice in the bottom right of the Bernstein diagram. In cloud environments, partitions are often mitigated with quorum and retries, so CAP isn’t the primary lens for design. Other tradeoffs, like latency vs. consistency or durability vs. performance, often matter more.
The real lesson here is that CAP is not a practical design guide for most engineers. It’s a useful theoretical boundary, but modern distributed systems operate in a more complex space of tradeoffs.