
Coffee Codex - How AWS Lambda Works (Part 2)
Introduction
I’m at Capital One Cafe in Bellevue, WA and I’m continuing to learn how Lambda works. In the last post, I wrote about the Lambda frontend and how a request actually gets routed to a server.

Let me recap the last few sentences:
Ok now let’s get to the workers! The simplest idea for workers is to match one request to one server. The obvious downside here is that Lambda has a limited number of servers. If you have a 1:1 matching, you will run out of servers to run on. With that being said, this approach is actually a great showing of what we want in a worker, specifically with security and isolation. You can’t get much more secure than running a function on a completely separate machine from another function, so there’s no possibility of your code impacting another customer. However we still want multi-tenancy, which is where one machine can handle multiple requests in an isolated way. The first thought is generally to use containers, but this wasn’t good enough for Lambda since containers still run on the same kernel… so Lambda had to find something else.
Hypervisors
Hypervisors do a lot of the heavy lifting when it comes to virtualization. They’re a layer of abstraction above the hardware that is able to give the illusion of each virtual machine having their own OS, filesystem, CPU, etc. There’s 2 types of hypervisors: Type 1 and Type 2.
Type 1 hypervisors sit on top of bare metal servers and can access hardware directly. This makes them very efficient since the host machine does not have an operating system installed on it. One of the most popular Type 1 hypervisors is Xen, which AWS used for EC2 for many years before eventually developing their own Nitro hypervisor.
Another example of a type 1 hypervisor is KVM (kernel virtual machine). Calling this a type 1 hypervisor is a bit confusing since technically the host is running Linux, but with KVM, the kernel becomes the hypervisor. We’ll talk more about KVM soon.
Type 2 hypervisors run on top of existing operating systems. Some examples of this include Virtualbox and Parallels, which you can install on your existing operating systems.
Given this, there are a few options for Lambda to take. Specifically, they could take advantage of a one-to-one mapping by using Xen, or they can use something like KVM and have a manager for it like QEMU.
Lambda on top of Xen
The first version of Lambda did something similar to our initial approach of mapping one request to one server. However these aren’t bare metal servers, but rather EC2 instances with Xen configured. Bare metal servers do not have a hypervisor and give you complete access to the server, whereas other instances have a hypervisor installed for multi-tenancy. So Lambda was able to piggy-back on top of EC2 instances with hypervisors in order to achieve their multitenancy goals as well.
But this approach didn’t have the performance benefits that Lambda wanted. Xen comes with a lot of overhead that was not needed for Lambda use cases and, importantly, didn’t have the instant boot times that Lambda needed.
KVM + QEMU
KVM is a great abstraction. As I mentioned before, it makes the OS the hypervisor and has low overhead. But KVM only provides the low level primitives and system calls like ioctl to manage things like memory, so there needs to be some sort of a monitor for these virtual machines… something like a Virtual Machine Monitor (VMM).
The VMM lives in userspace and uses the ioctl syscalls like this:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <linux/kvm.h>
#include <string.h>
#include <unistd.h>
#define GUEST_MEM_SIZE 0x400000 // 4 MB guest memory
int main(void) {
int kvm_fd, vm_fd, vcpu_fd;
int api_version;
struct kvm_userspace_memory_region region;
void *guest_mem;
size_t vcpu_mmap_size;
struct kvm_run *run;
// Open the KVM device.
kvm_fd = open("/dev/kvm", O_RDWR | O_CLOEXEC);
if (kvm_fd < 0) {
perror("open /dev/kvm");
exit(EXIT_FAILURE);
}
// Verify the API version.
api_version = ioctl(kvm_fd, KVM_GET_API_VERSION, 0);
if (api_version != KVM_API_VERSION) {
fprintf(stderr, "KVM API version mismatch: expected %d, got %d\n", KVM_API_VERSION, api_version);
exit(EXIT_FAILURE);
}
// Create a new virtual machine.
vm_fd = ioctl(kvm_fd, KVM_CREATE_VM, 0);
if (vm_fd < 0) {
perror("KVM_CREATE_VM");
exit(EXIT_FAILURE);
}
// Allocate guest memory.
guest_mem = mmap(NULL, GUEST_MEM_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (guest_mem == MAP_FAILED) {
perror("mmap guest memory");
exit(EXIT_FAILURE);
}
memset(guest_mem, 0, GUEST_MEM_SIZE);
// Set the guest memory region.
region.slot = 0;
region.flags = 0;
region.guest_phys_addr = 0x1000; // Starting guest physical address.
region.memory_size = GUEST_MEM_SIZE;
region.userspace_addr = (unsigned long) guest_mem;
if (ioctl(vm_fd, KVM_SET_USER_MEMORY_REGION, ®ion) < 0) {
perror("KVM_SET_USER_MEMORY_REGION");
exit(EXIT_FAILURE);
}
// Create a virtual CPU.
vcpu_fd = ioctl(vm_fd, KVM_CREATE_VCPU, 0);
if (vcpu_fd < 0) {
perror("KVM_CREATE_VCPU");
exit(EXIT_FAILURE);
}
// Get the size needed to map the vCPU's run structure.
vcpu_mmap_size = ioctl(kvm_fd, KVM_GET_VCPU_MMAP_SIZE, 0);
if (vcpu_mmap_size < sizeof(*run)) {
fprintf(stderr, "KVM_GET_VCPU_MMAP_SIZE too small\n");
exit(EXIT_FAILURE);
}
// Map the run structure.
run = mmap(NULL, vcpu_mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED, vcpu_fd, 0);
if (run == MAP_FAILED) {
perror("mmap vcpu");
exit(EXIT_FAILURE);
}
printf("KVM setup complete.\nGuest memory at %p, vCPU run structure at %p\n", guest_mem, run);
// Cleanup (in a real VMM, you'd now load guest code and enter a loop).
munmap(run, vcpu_mmap_size);
munmap(guest_mem, GUEST_MEM_SIZE);
close(vcpu_fd);
close(vm_fd);
close(kvm_fd);
return 0;
}A popular example of a VMM is QEMU, which was created in 2003. Since then, QEMU has grown to almost 2 million lines of code to support many types of guest architectures, devices, etc. Because of this, the performance of QEMU was a bit too slow for Lambda. And besides, Lambda controls the hardware they run on and the features/runtimes that are provided. So why not create something like QEMU that is hyperfitted for their use case?
That’s what Firecracker is.
Firecracker
Firecracker is a VMM that interacts with KVM to create microVMs for Lambda (and Fargate) requests. It was purpose-built to address the specific demands of serverless computing and containerized workloads (on Fargate), where efficiency, security, and rapid scale are crucial. Instead of running full-fledged virtual machines, Firecracker uses microVMs. microVMs provide many of the benefits of traditional VMs (such as strong isolation and hardware-assisted virtualization) but with much less resource overhead.
The high level overview of Firecracker looks like this
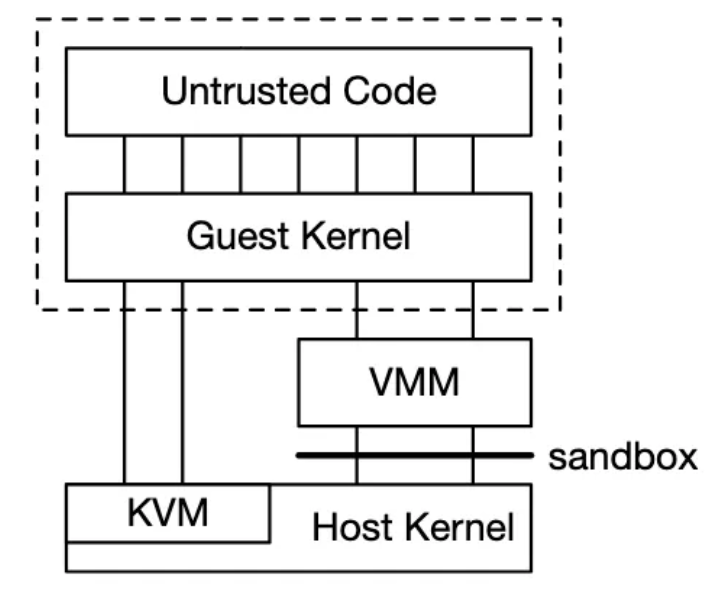
Untrusted code is the code that a user uploads to Lambda, while the guest kernel is the operating system kernel running inside the microVM.
The sandboxing is some of the techniques discussed in the last post like seccomp and chroot which offer an extra layer of security.
There’s one Firecracker process per Lambda invocation. So when the Placement Service needs to initialize an instance, it causes a new Firecracker process to start, and that Firecracker process will launch a new microVM to handle the request.
Slots
While booting up microVMs is fast since they’re fairly stripped down and don’t require support for legacy devices, they’re not instant. The Lambda servers (workers) have “slots” which are microVMs running with Firecracker. They stay warm for a while and can handle any request. Then when the lease expires or there’s a lot of traffic, the placement service will create a new one if needed.
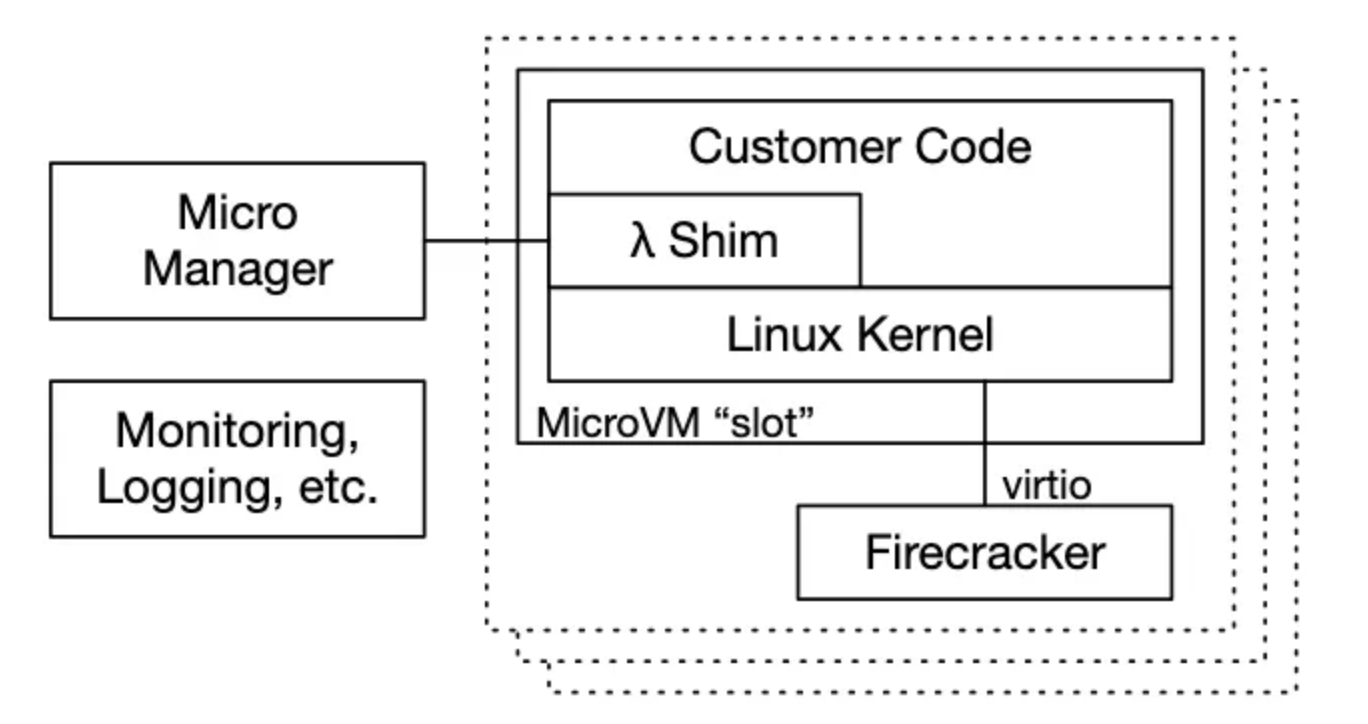
A cold start refers to when there are no slots for a customer, and a Firecracker process needs to be started and the microVM needs to be created. A warm start is the opposite, where a slot is ready to go and does not need to be initialized.
References
- https://www.usenix.org/system/files/nsdi20-paper-agache.pdf (Firecracker research paper)
- https://www.youtube.com/watch?v=0_jfH6qijVY (AWS re:Invent 2022 - A closer look at AWS Lambda)
- https://aws.amazon.com/what-is/hypervisor/