
Coffee Codex - Dropbox Magic Pocket I
Introduction
I’m at Toasted in Bellevue, WA and I’m learning about how Dropbox built Pocket Watch to verify exabytes of data from this Dropbox post

Introduction
I’ve been learning how S3 works recently and it’s fascinating how they manage millions of hard drives with incredible durability. Part of learning about S3 got me interestested in other storage solutions. I’ve also been looking into convex.dev and learned that the co-founder was a part of building Dropbox’s solution. Dropbox operates their own infrastructure and does not rely on S3 anymore so it’ll be interesting to see how the architectures differ.
Requirements of Magic Pocket
At it’s core, Dropbox stores content files and metadata files, the goal of Magic Pocket (MP) is to serve the content files. These files are split into blocks, replicated, and distributed across their data centers.
Immutable Block Storage - MP operates on 4MB immutable blocks that are content-addressed with some hash function like SHA-256. The immutablility makes their job a lot easier, since an update to a block does not have to modify an exiting block, it just creates a new one. This way, concurrent writes aren’t a big problem since each modification will create a new block. Those block versions are tracked in their FileJournal.
They also opted to use hard drives for their core storage (SSDs are used for database caches) because HDDs are cheap, durable, and storage-dense.
Durability - Of course, like S3, durability is right there are the top of requirements (security is probably more important). Data should persist in the case of drive failures, natural disasters, AZ failures, etc. The main discussion in paragraph is about erasure-coding but I’m sure we’ll get to more fun topics later in the article.
Scale - Without scale no one could use MP!. Since storage systems tend to be bursty, it’ll be interesting to see how Dropbox handles that. I wonder if they have the same convenience that S3 has where they operate at such a high scale that bursty behavior ends up becoming homogenous with millions of customers.
Simplicity - Essentially this means that they don’t want to reimplement Paxos and just leverages centralized coordination when they can. It’s a much simpler model and meets their needs.
Data Model
Ok now the fun part. Let’s say you have a file MyFile.xyz that is 8.1MB. Since Dropbox stores files as 4MB blocks, your file will be split up into 3 blocks.

From here, the blocks are compressed and encrypted. Because 4MB is a very small amount of data, it doesn’t make a lot of sense to operate on one block at a time when erasure coding. Because of this, MP aggregates the blocks into 1GB buckets. These buckets contain blocks they are not necessarily related to each other, they’re just uploaded around the same time.
From here, the blocks are put into a volume for storage.
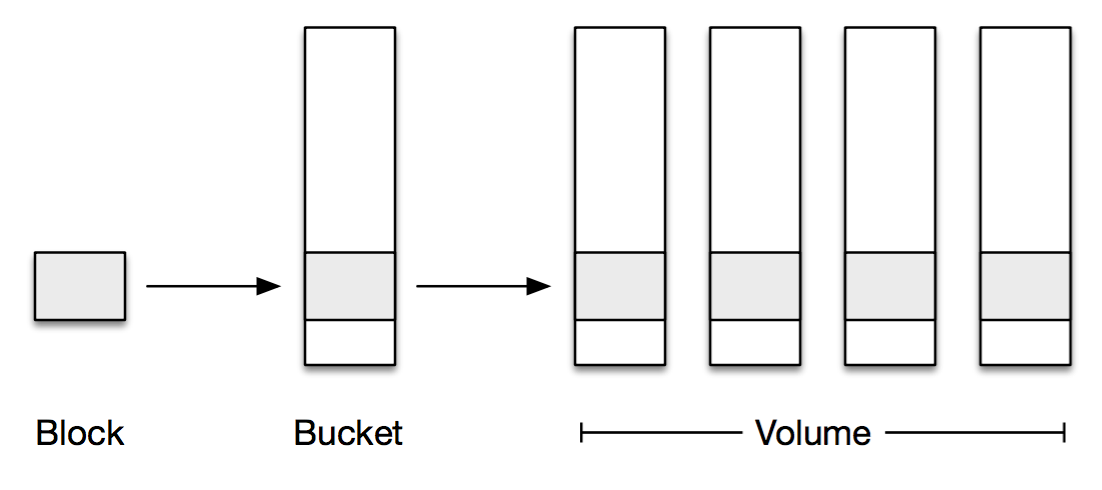
From what I can tell, the main reason why we can’t just skip the bucket step by making a block 1GB is because it’s unlikely that the majority of users have files that span multiple GB. This would increase latency significantly for smaller files.
Architecture
MP operates in multiple zones, think PDX, IAD, CMH, etc. The data is replicated through multiple zones (the post says 2+ but it could be more at this point) and then replicated across cells within a zone.
Next time I’ll explore more about the intra-zone architecture!