
Coffee Codex - Processes and Threads
Introduction
I’m at Royal Bakehouse in Bellevue WA and today I’m reading through this blog post from Ben Dicken at Planetscale.

What I know
I took an operating systems course in college so I should have a decent understanding of processes and threads, but it has been a while. I’m excited to see the visualizations in this blog post and hoping there are some applications to databases since I don’t know the concurrency model of different databases.
As a side note, I really like the font that Planetscale uses for their blogs.
Running one program
The first animation showcases a custom instruction-set architecture (ISA) that Ben made up. It’s similar to RISC-V with some slight syntax differences. It looks like for this blog post, we’ll be focusing on loading items into memory rather than registers. The first program we have is printing out even numbers. We do this by setting memory location 0 ($0) with the initial value of 0. Then we put the value 2 in $2 which serves as a constant we’ll be adding to the value in $1.
Running multiple programs
Of course, we typically don’t just run one program on a CPU, so we can introduce the idea of processes. In this animation we can do the job of the operating system, as we are the ones choosing when we should swap over to another process.
Although this sentence seems to indicate that it’s the CPU that is the one doing the timeslicing rather than the CPU scheduler which lives in the Kernel. I think it’s just an oversimplification for learning purposes.
This cycle continues until both programs complete. The CPU divides its time up into short time-slices, giving each process a burst of time to make progress.
Of course, on our computers it looks like there are multiple programs running at once. This is just because the time slices are so small that it appears instant in our brains.
The process (haha) of switching to a different process is called a context switch, and context switches come with a cost of around 5 microseconds. This is tens of thousands of instructions happening each second just for context switching. Even though it is significant, typically this tradeoff is worth it for the process abstraction. The powerful thing about processes is they are independent from other processes, meaning they have their own address space, registers, and resources. The same can’t be said for threads.
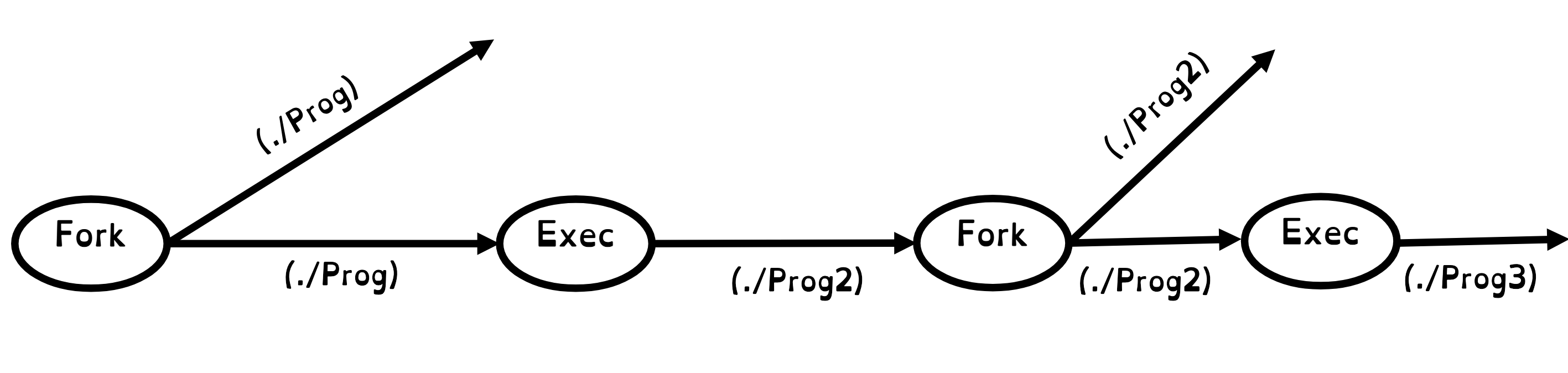
Creating a new process typically involves the fork-exec pattern, where a parent process calls fork which creates a clone of the current program. Then, we call exec to change the program depending on whether we’re in the parent or child process.
cpid = fork();
if (cpid > 0) { /* Parent Process */
……
} else if (cpid == 0) { /* Child Process */
char *args[] = {“ls”, “-l”, NULL};
execv(“/bin/ls”, args);
/* execv doesn’t return when it works.
So, if we got here, it failed! */
perror(“execv”);
exit(1);
}Threads
There are two types of threads: kernel threads and user threads. Kernel threads map 1:1 to threads the OS sees, whereas user threads exist purely in user space. User threads are also called green threads and are implemented in languages like Go (goroutines). We can create a kernel thread using pthread_create. Threads don’t run in their own address space, they share the same address space as the process that created them. This means threads can access the same memory, which makes communication between threads much faster than inter-process communication, but also means threads need to be careful about synchronization when accessing shared resources.
Database applications
Postgres uses a connection-per-process model, while MySQL uses connection-per-thread. This is interesting since this objectively means that Postgres spends a lot more time context switching between processes than MySQL. I’m curious to hear more thoughts about this from Planetscale, since I’m sure they spend a lot of time thinking about these tradeoffs. Surely there must be places where the Postgres model is more advantageous but I didn’t get that from this blog post. There’s better isolation between processes, but even that doesn’t seem to matter too much considering databases typically pool connections.
Connection pooling is the idea of having a middleman between the client and DB that serves the role of a load balancer. The connection pooler has 5 - 50 connections always open, and the client requests use one of these open connections. This helps reduce the overhead of establishing new connections for each client request, which can be expensive especially in Postgres’s process-per-connection model.
I’d like to read more about how the choice between process-per-connection vs thread-per-connection also affects how the database handles crashes and isolation.
Really cool blog post by Ben!